Reference genome
Loading a reference genome#
IGV requires a reference genome. It serves as the "coordinate system" for displaying the tracks. When you first launch IGV, the human genome GRCh38/hg38 is loaded by default. The genome dropdown menu on the left end of the IGV window toolbar displays the current reference genome, and contains a selection list of recently loaded genomes.
![]()
Options for changing loading a genome not yet on the selection list are described below and include
- selecting a predefined genome from the "hosted genome" list,
- loading a UCSC track hub.
- loading a custom genome
jsonor sequence file,
These options are available under the Genomes menu
When you switch to a different reference genome, IGV will clear the current session.
Select a hosted genome#
IGV provides a limited selection of predefined genome definitions. The list can be accessed from the Genomes menu
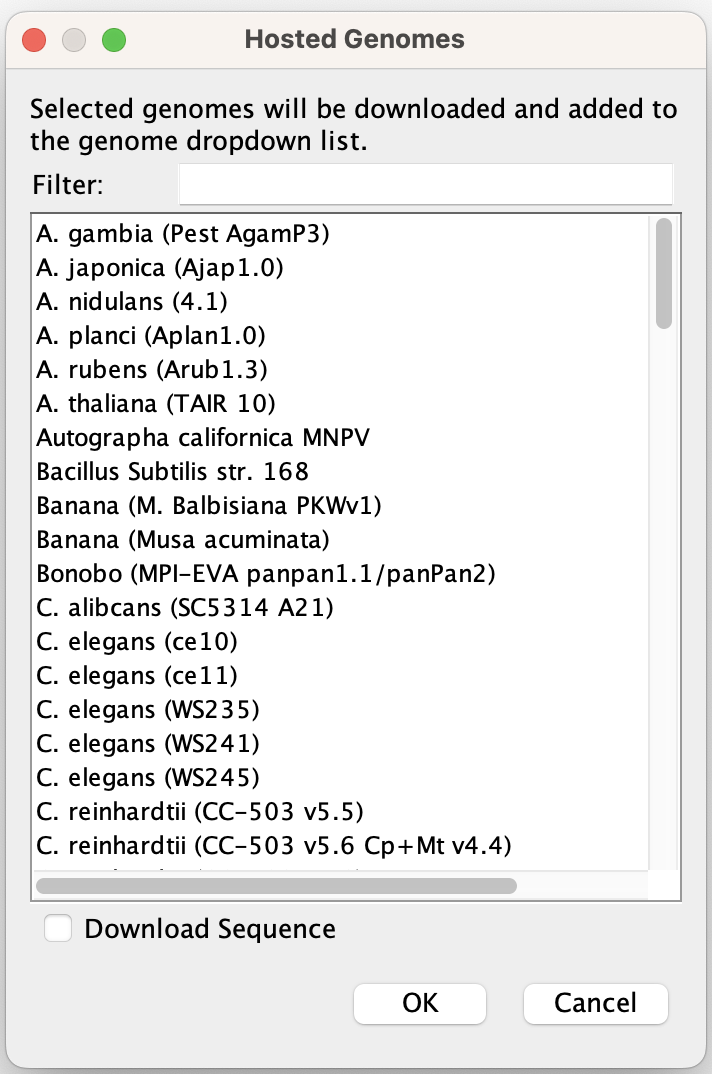
- Select Genomes > Select Hosted Genome
This will pop up a window with the full list of hosted genomes. If you find your genome of interest there, select it and click ok. Your selected genome will replace the reference genome in the main IGV window. Once you have selected a genome from the full list, it will remain in the genome dropdown menu in the toolbar.
See the Advanced section below for information on how to host your own customized list of genomes.
IGV's hosted genomes require an internet connection. See the Advanced section below for information on how to download a hosted genome for offline use of IGV.
Load a UCSC GenArk track hub#
Reference genome assemblies and associated tracks can be loaded directly from the UCSC GenArk archive.
Select Genomes > Load Genome from UCSC GenArk… to bring up a table of all available assemblies. The table can
be filtered by typing space separated terms in filter box.
After selecting an assembly you will be prompted to select from the available annotation tracks. Once you've
made your selections, the genome will be added to the genome dropdown menu and the anntation tracks will be displayed
whenever you select the genome from the menu. You can change the selection of annotation tracks via Genomes > Select GenArk Tracks.
For more information on the GenArk resource see
Clawson, H., Lee, B.T., Raney, B.J. et al. GenArk: towards a million UCSC genome browsers. Genome Biol 24, 217 (2023).
https://doi.org/10.1186/s13059-023-03057-x
Track hub support is not limited to the GenArk site, but includes any hub in the useOneFile format (see the documentation on track hub settings) at the UCSC site.
Define a custom genome#
To load a reference genome that is not included in IGV's set of hosted genomes, you can load a file the specifies the genome by clicking on Genomes > Load Genome from File or Genomes > Load Genome from URL. The following file types are supported for defining a custom genome (1) Fasta and .2bit sequence files, (2) IGV genome json* files, and (3) NBCI genbank (.gbk) files.
Sequence file#
A reference genome can be defined by loading a FASTA or .2bit file for the genome sequence. With this option the gene annotations will not be loaded automatically. However, annotation files can be loaded from the *Files > Load from menus.
FASTA files can be plain text or block gzipped, and must be indexed with a .fai as defined by the Samtools suite (www.htslib.org). If the file is plain text (not block gzipped) and not indexed, IGV will attempt to index it.
Genome json file#
To automatically load gene annotations, as well as an optional cytoband file, along with the genome sequence, you can create and load a genome JSON file, which is described in the File Formats: Genomes section.
Removing a genome from the menu#
When you have loaded a reference genome, it will remain in the genome dropdown menu unless you remove it.
To remove a genome from the dropdown menu:
- Select Genomes>Remove Genomes.
- Select the genomes you want to remove and click Remove.
You cannot remove the genome that is currently being used in the IGV window.
Viewing the reference genome tracks#
All genomes include a reference sequence track, and optionally can define one or more annotation tracks. See the following sections for more infomation on reference and annotation track conventions.
Advanced#
Hosting genomes#
The list of hosted reference genomes in the IGV menus is defined by the file specified in the Genome server URL field of the Advanced tab of the View > Preferences window. By default, the Genome server URL is set to a file hosted at https://igv.org. You may wish to replace it with your own customized list of genomes for a variety of reasons. For example, to limit the list to only those genomes that are of interest to you and your colleagues or to add a genome that is not included with the default hosted genomes.
To host your own customized list of reference genomes:
-
Create a text file listing all the genomes you wish to include in the hosted genomes menu. The file format is described below.
-
Upload the file to your web server.
-
Start IGV. Select View > Preferences > Advanced and set the Genome server URL to the URL to your genomes file on your server.
-
Shut down IGV. Upon restart your hosted genome list will be used in place of the default list.
The file format for the reference genome list defines one genome per line with three tab-delimited columns:
-
The genome name, which will appear in the menu.
-
A URL to a .json or .genome file that specifies the details of the genome. This can point to a file from IGV's default list or your own custom genome file that you have uploaded to a web server.
The .json format for reference genomes is described here. Use this format to define any custom genomes you wish to add the list. The .genome format is an older format and is supported only for backwards compatibility with existing .genome files.
- The genome ID. The ID is arbitrary, but for genomes from UCSC use their ID. This is important for the BLAT tool, which uses the UCSC BLAT server.
To use IGV's default genome list file as a starting point for your new file, you can download it from https://igv.org/genomes/genomes.tsv.